Acknowledgement
Most of the information in this blog post is sourced from Machine Learning Mastery.
Also read All you need to know about ‘Attention’ and ‘Transformers’ — In-depth Understanding — Part 1 and All you need to know about ‘Attention’ and ‘Transformers’ — In-depth Understanding — Part 2.
The Attention Mechanism from Scratch
The attention mechanism was introduced to improve the performance of the encoder-decoder model for machine translation. The idea behind the attention mechanism was to permit the decoder to utilize the most relevant parts of the input sequence in a flexible manner, by a weighted combination of all the encoded input vectors, with the most relevant vectors being attributed the highest weights.
After completing this tutorial, you will know:
- How the attention mechanism uses a weighted sum of all the encoder hidden states to flexibly focus the attention of the decoder on the most relevant parts of the input sequence
- How the attention mechanism can be generalized for tasks where the information may not necessarily be related in a sequential fashion
- How to implement the general attention mechanism in Python with NumPy and SciPy
The Attention Mechanism
The attention mechanism was introduced by Bahdanau et al. (2014) to address the bottleneck problem that arises with the use of a fixed-length encoding vector, where the decoder would have limited access to the information provided by the input. This is thought to become especially problematic for long and/or complex sequences, where the dimensionality of their representation would be forced to be the same as for shorter or simpler sequences.
Note that Bahdanau et al.’s attention mechanism is divided into the step-by-step computations of the alignment scores, the weights, and the context vector:
- Alignment scores: The alignment model takes the encoded hidden states, , and the previous decoder output, , to compute a score, , that indicates how well the elements of the input sequence align with the current output at the position, . The alignment model is represented by a function, , which can be implemented by a feedforward neural network:
- Weights: The weights, , are computed by applying a softmax operation to the previously computed alignment scores:
- Context vector: A unique context vector, , is fed into the decoder at each time step. It is computed by a weighted sum of all, , encoder hidden states:
Bahdanau et al. implemented an RNN for both the encoder and decoder.
However, the attention mechanism can be re-formulated into a general form that can be applied to any sequence-to-sequence (abbreviated to seq2seq) task, where the information may not necessarily be related in a sequential fashion.
In other words, the database doesn’t have to consist of the hidden RNN states at different steps, but could contain any kind of information instead.
– Advanced Deep Learning with Python, 2019.
The General Attention Mechanism
The general attention mechanism makes use of three main components, namely the queries, , the keys, , and the values, .
If you had to compare these three components to the attention mechanism as proposed by Bahdanau et al., then the query would be analogous to the previous decoder output, , while the values would be analogous to the encoded inputs, . In the Bahdanau attention mechanism, the keys and values are the same vector.
In this case, we can think of the vector as a query executed against a database of key-value pairs, where the keys are vectors and the hidden states are the values.
– Advanced Deep Learning with Python, 2019.
The general attention mechanism then performs the following computations:
- Each query vector, , is matched against a database of keys to compute a score value. This matching operation is computed as the dot product of the specific query under consideration with each key vector, :
- The scores are passed through a softmax operation to generate the weights:
- The generalized attention is then computed by a weighted sum of the value vectors, , where each value vector is paired with a corresponding key:
Within the context of machine translation, each word in an input sentence would be attributed its own query, key, and value vectors. These vectors are generated by multiplying the encoder’s representation of the specific word under consideration with three different weight matrices that would have been generated during training.
In essence, when the generalized attention mechanism is presented
with a sequence of words, it takes the query vector attributed to some
specific word in the sequence and scores it against each key in the
database. In doing so, it captures how the word under consideration
relates to the others in the sequence. Then it scales the values
according to the attention weights (computed from the scores) to retain
focus on those words relevant to the query. In doing so, it produces an
attention output for the word under consideration.
The Bahdanau Attention Mechanism
Conventional encoder-decoder architectures for machine translation encoded every source sentence into a fixed-length vector, regardless of its length, from which the decoder would then generate a translation. This made it difficult for the neural network to cope with long sentences, essentially resulting in a performance bottleneck.
The Bahdanau attention was proposed to address the performance bottleneck of conventional encoder-decoder architectures, achieving significant improvements over the conventional approach.
In this tutorial, you will discover the Bahdanau attention mechanism for neural machine translation.
After completing this tutorial, you will know:
- Where the Bahdanau attention derives its name from and the challenge it addresses
- The role of the different components that form part of the Bahdanau encoder-decoder architecture
- The operations performed by the Bahdanau attention algorithm
Tutorial Overview
This tutorial is divided into two parts; they are:
- Introduction to the Bahdanau Attention
- The Bahdanau Architecture
- The Encoder
- The Decoder
- The Bahdanau Attention Algorithm
Prerequisites
For this tutorial, we assume that you are already familiar with:
- Recurrent Neural Networks (RNNs)
- The encoder-decoder RNN architecture
- The concept of attention
- The attention mechanism
Introduction to the Bahdanau Attention
The Bahdanau attention mechanism inherited its name from the first author of the paper in which it was published.
It follows the work of Cho et al. (2014) and Sutskever et al. (2014), who also employed an RNN encoder-decoder framework for neural machine translation, specifically by encoding a variable-length source sentence into a fixed-length vector. The latter would then be decoded into a variable-length target sentence.
Bahdanau et al. (2014) argued that this encoding of a variable-length input into a fixed-length vector squashes the information of the source sentence, irrespective of its length, causing the performance of a basic encoder-decoder model to deteriorate rapidly with an increasing length of the input sentence. The approach they proposed replaces the fixed-length vector with a variable-length one to improve the translation performance of the basic encoder-decoder model.
The most important distinguishing feature of this approach from the basic encoder-decoder is that it does not attempt to encode a whole input sentence into a single fixed-length vector. Instead, it encodes the input sentence into a sequence of vectors and chooses a subset of these vectors adaptively while decoding the translation.
– Neural Machine Translation by Jointly Learning to Align and Translate, 2014.
The Bahdanau Architecture
The main components in use by the Bahdanau encoder-decoder architecture are the following:
- is the hidden decoder state at the previous time step, .
- is the context vector at time step, . It is uniquely generated at each decoder step to generate a target word, .
- is an annotation that captures the information contained in the words forming the entire input sentence, , with strong focus around the -th word out of total words.
- is a weight value assigned to each annotation, , at the current time step, .
- is an attention score generated by an alignment model, , that scores how well and match.
These components find their use at different stages of the Bahdanau architecture, which employs a bidirectional RNN as an encoder and an RNN decoder, with an attention mechanism in between:

The Bahdanau architecture
The Encoder
The role of the encoder is to generate an annotation, , for every word, , in an input sentence of length words.
For this purpose, Bahdanau et al. employ a bidirectional RNN, which reads the input sentence in the forward direction to produce a forward hidden state, , and then reads the input sentence in the reverse direction to produce a backward hidden state, . The annotation for some particular word, , concatenates the two states:
The idea behind generating each annotation in this manner was to capture a summary of both the preceding and succeeding words.
In this way, the annotation contains the summaries of both the preceding words and the following words.
– Neural Machine Translation by Jointly Learning to Align and Translate, 2014.
The generated annotations are then passed to the decoder to generate the context vector.
The Decoder
The role of the decoder is to produce the target words by focusing on the most relevant information contained in the source sentence. For this purpose, it makes use of an attention mechanism.
Each time the proposed model generates a word in a translation, it (soft-)searches for a set of positions in a source sentence where the most relevant information is concentrated. The model then predicts a target word based on the context vectors associated with these source positions and all the previous generated target words.
– Neural Machine Translation by Jointly Learning to Align and Translate, 2014.
The decoder takes each annotation and feeds it to an alignment model, , together with the previous hidden decoder state, . This generates an attention score:
The function implemented by the alignment model here combines and using an addition operation. For this reason, the attention mechanism implemented by Bahdanau et al. is referred to as additive attention.
This can be implemented in two ways, either (1) by applying a weight matrix, , over the concatenated vectors, and , or (2) by applying the weight matrices, and , to and separately:
Here, is a weight vector.
The alignment model is parametrized as a feedforward neural network and jointly trained with the remaining system components.
Subsequently, a softmax function is applied to each attention score to obtain the corresponding weight value:
The application of the softmax function essentially normalizes the annotation values to a range between 0 and 1; hence, the resulting weights can be considered probability values. Each probability (or weight) value reflects how important and are in generating the next state, , and the next output, .
Intuitively, this implements a mechanism of attention in the decoder. The decoder decides parts of the source sentence to pay attention to. By letting the decoder have an attention mechanism, we relieve the encoder from the burden of having to encode all information in the source sentence into a fixed-length vector.
– Neural Machine Translation by Jointly Learning to Align and Translate, 2014.
This is finally followed by the computation of the context vector as a weighted sum of the annotations:
The Bahdanau Attention Algorithm
In summary, the attention algorithm proposed by Bahdanau et al. performs the following operations:
- The encoder generates a set of annotations, , from the input sentence.
- These annotations are fed to an alignment model and the previous hidden decoder state. The alignment model uses this information to generate the attention scores, .
- A softmax function is applied to the attention scores, effectively normalizing them into weight values, , in a range between 0 and 1.
- Together with the previously computed annotations, these weights are used to generate a context vector, , through a weighted sum of the annotations.
- The context vector is fed to the decoder together with the previous hidden decoder state and the previous output to compute the final output, .
- Steps 2-6 are repeated until the end of the sequence.
Bahdanau et al. tested their architecture on the task of English-to-French translation. They reported that their model significantly outperformed the conventional encoder-decoder model, regardless of the sentence length.
There have been several improvements over the Bahdanau attention proposed, such as those of Luong et al. (2015), which we shall review in a separate tutorial.
Further Reading
The Luong Attention Mechanism
The Luong attention sought to introduce several improvements over the Bahdanau model for neural machine translation, notably by introducing two new classes of attentional mechanisms: a global approach that attends to all source words and a local approach that only attends to a selected subset of words in predicting the target sentence.
Prerequisites
For this tutorial, we assume that you are already familiar with:
Introduction to the Luong Attention
Luong et al. (2015) inspire themselves from previous attention models to propose two attention mechanisms:
In this work, we design, with simplicity and effectiveness in mind, two novel types of attention-based models: a global approach which always attends to all source words and a local one that only looks at a subset of source words at a time.
– Effective Approaches to Attention-based Neural Machine Translation, 2015.
The global attentional model resembles the Bahdanau et al. (2014) model in attending to all source words but aims to simplify it architecturally.
The local attentional model is inspired by the hard and soft attention models of Xu et al. (2016) and attends to only a few of the source positions.
The two attentional models share many of the steps in their prediction of the current word but differ mainly in their computation of the context vector.
Let’s first take a look at the overarching Luong attention algorithm and then delve into the differences between the global and local attentional models afterward.
The Luong Attention Algorithm
The attention algorithm of Luong et al. performs the following operations:
- The encoder generates a set of annotations, , from the input sentence.
- The current decoder hidden state is computed as: . Here, denotes the previous hidden decoder state and the previous decoder output.
- An alignment model, , uses the annotations and the current decoder hidden state to compute the alignment scores: .
- A softmax function is applied to the alignment scores, effectively normalizing them into weight values in a range between 0 and 1: .
- Together with the previously computed annotations, these weights are used to generate a context vector through a weighted sum of the annotations: .
- An attentional hidden state is computed based on a weighted concatenation of the context vector and the current decoder hidden state: .
- The decoder produces a final output by feeding it a weighted attentional hidden state: .
- Steps 2-7 are repeated until the end of the sequence.
The Global Attentional Model
The global attentional model considers all the source words in the input sentence when generating the alignment scores and, eventually, when computing the context vector.
The idea of a global attentional model is to consider all the hidden states of the encoder when deriving the context vector, .
– Effective Approaches to Attention-based Neural Machine Translation, 2015.
In order to do so, Luong et al. propose three alternative approaches for computing the alignment scores. The first approach is similar to Bahdanau’s. It is based upon the concatenation of and , while the second and third approaches implement multiplicative attention (in contrast to Bahdanau’s additive attention):
Here, is a trainable weight matrix, and similarly, is a weight vector.
Intuitively, the use of the dot product in multiplicative attention can be interpreted as providing a similarity measure between the vectors, and , under consideration.
… if the vectors are similar (that is, aligned), the result of the multiplication will be a large value and the attention will be focused on the current t,i relationship.
– Advanced Deep Learning with Python, 2019.
The resulting alignment vector, , is of a variable length according to the number of source words.
The Local Attentional Model
In attending to all source words, the global attentional model is computationally expensive and could potentially become impractical for translating longer sentences.
The local attentional model seeks to address these limitations by focusing on a smaller subset of the source words to generate each target word. In order to do so, it takes inspiration from the hard and soft attention models of the image caption generation work of Xu et al. (2016):
- Soft attention is equivalent to the global attention approach, where weights are softly placed over all the source image patches. Hence, soft attention considers the source image in its entirety.
- Hard attention attends to a single image patch at a time.
The local attentional model of Luong et al. generates a context vector by computing a weighted average over the set of annotations, , within a window centered over an aligned position, :
While a value for is selected empirically, Luong et al. consider two approaches in computing a value for :
- Monotonic alignment: where the source and target sentences are assumed to be monotonically aligned and, hence, .
- Predictive alignment: where a prediction of the aligned position is based upon trainable model parameters, and , and the source sentence length, :
A Gaussian distribution is centered around when computing the alignment weights to favor source words nearer to the window center.
This time round, the resulting alignment vector, , has a fixed length of .
Comparison to the Bahdanau Attention
The Bahdanau model and the global attention approach of Luong et al. are mostly similar, but there are key differences between the two:
While our global attention approach is similar in spirit to the model proposed by Bahdanau et al. (2015), there are several key differences which reflect how we have both simplified and generalized from the original model.
– Effective Approaches to Attention-based Neural Machine Translation, 2015.
- Most notably, the computation of the alignment scores, , in the Luong global attentional model depends on the current decoder hidden state, , rather than on the previous hidden state, , as in the Bahdanau attention.
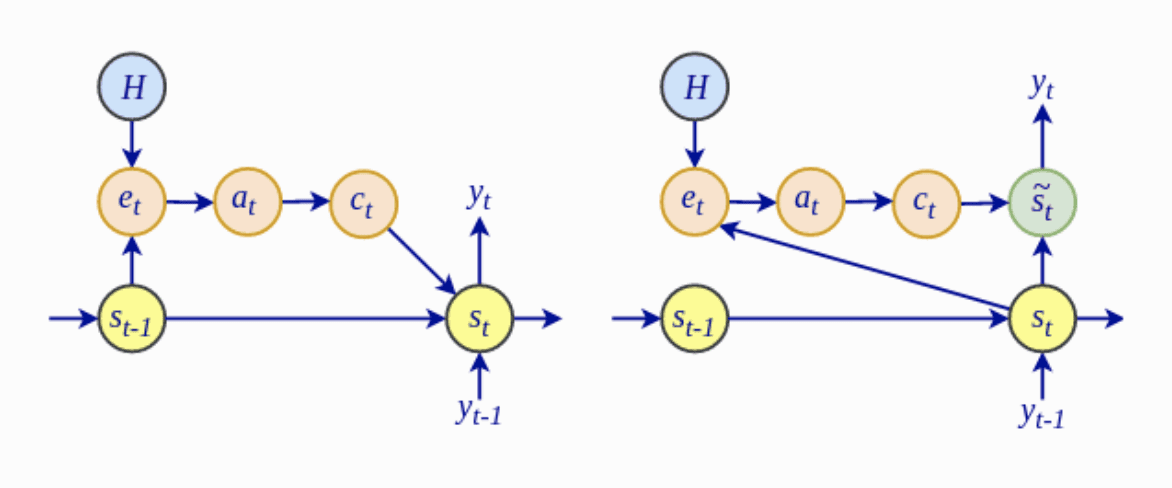
The Bahdanau architecture (left) vs. the Luong architecture (right)
- Luong et al. drop the bidirectional encoder used by the Bahdanau model and instead utilize the hidden states at the top LSTM layers for both the encoder and decoder.
- The global attentional model of Luong et al. investigates the use of multiplicative attention as an alternative to the Bahdanau additive attention.
Further Reading
- Advanced Deep Learning with Python, 2019.
- Effective Approaches to Attention-based Neural Machine Translation, 2015.
The Transformer Attention Mechanism
Before the introduction of the Transformer model, the use of attention for neural machine translation was implemented by RNN-based encoder-decoder architectures. The Transformer model revolutionized the implementation of attention by dispensing with recurrence and convolutions and, alternatively, relying solely on a self-attention mechanism.
We will first focus on the Transformer attention mechanism in this tutorial and subsequently review the Transformer model in a separate one.
In this tutorial, you will discover the Transformer attention mechanism for neural machine translation.
After completing this tutorial, you will know:
- How the Transformer attention differed from its predecessors
- How the Transformer computes a scaled-dot product attention
- How the Transformer computes multi-head attention
For this tutorial, we assume that you are already familiar with:
- The concept of attention
- The attention mechanism
- The Bahdanau attention mechanism
- The Luong attention mechanism
Introduction to the Transformer Attention
Thus far, you have familiarized yourself with using an attention mechanism in conjunction with an RNN-based encoder-decoder architecture. Two of the most popular models that implement attention in this manner have been those proposed by Bahdanau et al. (2014) and Luong et al. (2015).
The Transformer architecture revolutionized the use of attention by dispensing with recurrence and convolutions, on which the formers had extensively relied.
… the Transformer is the first transduction model relying entirely on self-attention to compute representations of its input and output without using sequence-aligned RNNs or convolution.
– Attention Is All You Need, 2017.
In their paper, “Attention Is All You Need,” Vaswani et al. (2017) explain that the Transformer model, alternatively, relies solely on the use of self-attention, where the representation of a sequence (or sentence) is computed by relating different words in the same sequence.
Self-attention, sometimes called intra-attention, is an attention mechanism relating different positions of a single sequence in order to compute a representation of the sequence.
– Attention Is All You Need, 2017.
The Transformer Attention
The main components used by the Transformer attention are the following:
- and denoting vectors of dimension, , containing the queries and keys, respectively
- denoting a vector of dimension, , containing the values
- , , and denoting matrices packing together sets of queries, keys, and values, respectively.
- , and denoting projection matrices that are used in generating different subspace representations of the query, key, and value matrices
- denoting a projection matrix for the multi-head output
In essence, the attention function can be considered a mapping between a query and a set of key-value pairs to an output.
The output is computed as a weighted sum of the values, where the weight assigned to each value is computed by a compatibility function of the query with the corresponding key.
– Attention Is All You Need, 2017.
Vaswani et al. propose a scaled dot-product attention and then build on it to propose multi-head attention. Within the context of neural machine translation, the query, keys, and values that are used as inputs to these attention mechanisms are different projections of the same input sentence.
Intuitively, therefore, the proposed attention mechanisms implement self-attention by capturing the relationships between the different elements (in this case, the words) of the same sentence.
Scaled Dot-Product Attention
The Transformer implements a scaled dot-product attention, which follows the procedure of the general attention mechanism that you had previously seen.
As the name suggests, the scaled dot-product attention first computes a dot product for each query, , with all of the keys, . It subsequently divides each result by and proceeds to apply a softmax function. In doing so, it obtains the weights that are used to scale the values, .
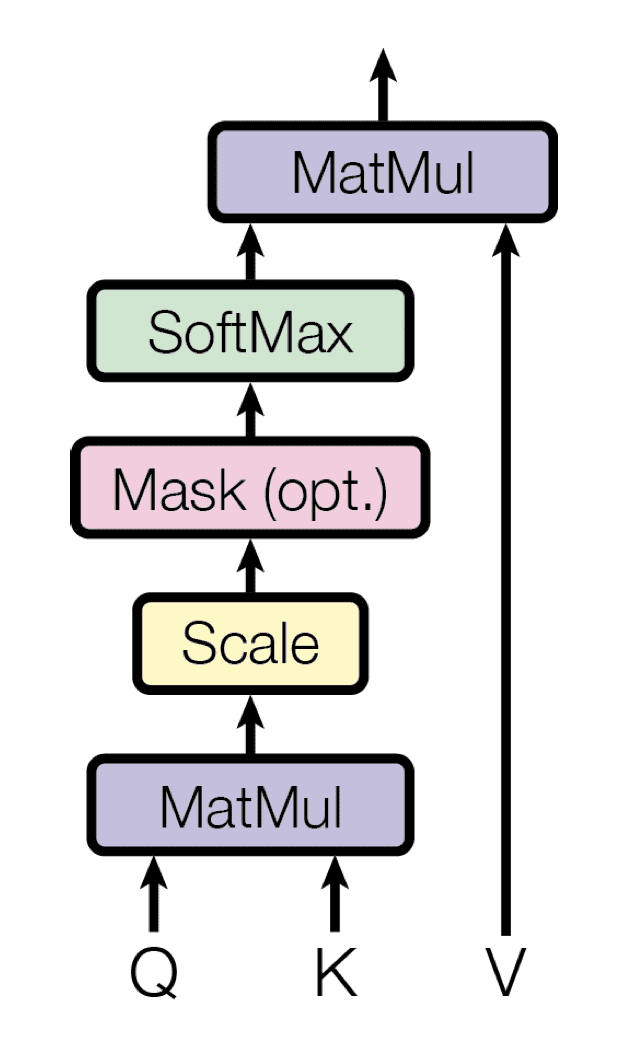
Scaled dot-product attention (Taken from “Attention Is All You Need“)
In practice, the computations performed by the scaled dot-product attention can be efficiently applied to the entire set of queries simultaneously. In order to do so, the matrices—, , and —are supplied as inputs to the attention function:
Vaswani et al. explain that their scaled dot-product attention is identical to the multiplicative attention of Luong et al. (2015), except for the added scaling factor of .
This scaling factor was introduced to counteract the effect of having the dot products grow large in magnitude for large values of , where the application of the softmax function would then return extremely small gradients that would lead to the infamous vanishing gradients problem. The scaling factor, therefore, serves to pull the results generated by the dot product multiplication down, preventing this problem.
Vaswani et al. further explain that their choice of opting for multiplicative attention instead of the additive attention of Bahdanau et al. (2014) was based on the computational efficiency associated with the former.
… dot-product attention is much faster and more space-efficient in practice since it can be implemented using highly optimized matrix multiplication code.
– Attention Is All You Need, 2017.
Therefore, the step-by-step procedure for computing the scaled-dot product attention is the following:
- Compute the alignment scores by multiplying the set of queries packed in the matrix, , with the keys in the matrix, . If the matrix, , is of the size , and the matrix, , is of the size, , then the resulting matrix will be of the size :
- Scale each of the alignment scores by :
- And follow the scaling process by applying a softmax operation in order to obtain a set of weights:
- Finally, apply the resulting weights to the values in the matrix, , of the size, :
Multi-Head Attention
Building on their single attention function that takes matrices, , , and , as input, as you have just reviewed, Vaswani et al. also propose a multi-head attention mechanism.
Their multi-head attention mechanism linearly projects the queries, keys, and values times, using a different learned projection each time. The single attention mechanism is then applied to each of these projections in parallel to produce outputs, which, in turn, are concatenated and projected again to produce a final result.

Multi-head attention (Taken from “Attention Is All You Need“)
The idea behind multi-head attention is to allow the attention function to extract information from different representation subspaces, which would otherwise be impossible with a single attention head.
The multi-head attention function can be represented as follows:
Here, each , , implements a single attention function characterized by its own learned projection matrices:
The step-by-step procedure for computing multi-head attention is, therefore, the following:
- Compute the linearly projected versions of the queries, keys, and values through multiplication with the respective weight matrices, , , and , one for each .
- Apply the single attention function for each head by (1) multiplying the queries and keys matrices, (2) applying the scaling and softmax operations, and (3) weighting the values matrix to generate an output for each head.
- Concatenate the outputs of the heads, , .
- Apply a linear projection to the concatenated output through multiplication with the weight matrix, , to generate the final result.




